 \n\n一般来说,B树也是一个自平衡的二叉搜索树。但与红黑树不同的是,B树的节点可以存储多个元素,m mm阶B树的单个节点,最多有 m − 1 m-1m−1 个元素、m mm 个子节点。并且B树只有孩子节点、没有父节点(没有向上的指针)。也就是说,对于插入/删除操作,红黑树可以先从上往下寻找插入位置,再从下往上进行调整;而B树要先从上往下调整完(“分裂、合并/借位”),最后在叶子节点进行插入/删除,而没有从下往上的过程。即进行插入/删除时,B树从上往下只走一次。下面给出一个 m mm阶B树应该满足的条件(判断一棵B树是否有效的依据):\n\n同样的,B树的查找操作只需要从根节点不断比较即可,而B树的插入/删除逻辑如下:\n\n **B树插入** :从上往下寻找要插入的叶子节点,过程中要下去的孩子若是满节点,则进行“分裂”。\n\n **B树删除** :从上往下寻找要删除元素的所在节点,过程中看情况进行“合并/借位”。若所在节点不是叶子节点,就将其换到叶子节点中。最后在叶子节点删除元素。\n\n\n\n```\n// 遍历到叶子节点\nwhile(不是叶子节点){\n // 1. 确定下一节点和其兄弟节点\n if(当前节点有要删除的元素) 哪边少哪边就是下一节点,当前元素对应的另一边就是兄弟节点。\n else(当前节点没有要删除的元素) 确定好要去的下一节点后,左右两边谁多谁是兄弟节点。\n // 2. 看是否需要调整\n if(下一节点元素少){\n if(孩子的兄弟节点元素多) 借位,进入下一节点。\n else(孩子的兄弟节点元素少) 合并,进入合并后的节点。\n }else if(下一节点元素多 && 当前节点有要删除元素){\n if(下一节点是删除元素的左节点) 删除元素和其前驱元素换位,进入下一节点。\n else(下一节点是删除元素的右节点) 删除元素和其后继元素换位,进入下一节点。\n }else{\n 直接进入下一节点。\n }\n}\n// 然后在叶子节点删除元素\n```\n\n注:判断孩子节点的元素少的条件是 元素数量≤ ceil m/2 -1,判断元素多的条件是 元素数量≥ ceil m/2。\n\n根据上述原理,我使用C语言实现了B树完整的 **增删查** 操作,并增加了 **检验有效性** 、 **打印B树** 的代码,以及 **测试代码(终端显示进度条)** 。同样为了加快开发速度,预设“键值对”的类型为、,后续将B树添加进“kv存储协议”中时会进一步修改:\n\n **btree_int.c** -共989行\n\n\n\n```\n#include
\n\n一般来说,B树也是一个自平衡的二叉搜索树。但与红黑树不同的是,B树的节点可以存储多个元素,m mm阶B树的单个节点,最多有 m − 1 m-1m−1 个元素、m mm 个子节点。并且B树只有孩子节点、没有父节点(没有向上的指针)。也就是说,对于插入/删除操作,红黑树可以先从上往下寻找插入位置,再从下往上进行调整;而B树要先从上往下调整完(“分裂、合并/借位”),最后在叶子节点进行插入/删除,而没有从下往上的过程。即进行插入/删除时,B树从上往下只走一次。下面给出一个 m mm阶B树应该满足的条件(判断一棵B树是否有效的依据):\n\n同样的,B树的查找操作只需要从根节点不断比较即可,而B树的插入/删除逻辑如下:\n\n **B树插入** :从上往下寻找要插入的叶子节点,过程中要下去的孩子若是满节点,则进行“分裂”。\n\n **B树删除** :从上往下寻找要删除元素的所在节点,过程中看情况进行“合并/借位”。若所在节点不是叶子节点,就将其换到叶子节点中。最后在叶子节点删除元素。\n\n\n\n```\n// 遍历到叶子节点\nwhile(不是叶子节点){\n // 1. 确定下一节点和其兄弟节点\n if(当前节点有要删除的元素) 哪边少哪边就是下一节点,当前元素对应的另一边就是兄弟节点。\n else(当前节点没有要删除的元素) 确定好要去的下一节点后,左右两边谁多谁是兄弟节点。\n // 2. 看是否需要调整\n if(下一节点元素少){\n if(孩子的兄弟节点元素多) 借位,进入下一节点。\n else(孩子的兄弟节点元素少) 合并,进入合并后的节点。\n }else if(下一节点元素多 && 当前节点有要删除元素){\n if(下一节点是删除元素的左节点) 删除元素和其前驱元素换位,进入下一节点。\n else(下一节点是删除元素的右节点) 删除元素和其后继元素换位,进入下一节点。\n }else{\n 直接进入下一节点。\n }\n}\n// 然后在叶子节点删除元素\n```\n\n注:判断孩子节点的元素少的条件是 元素数量≤ ceil m/2 -1,判断元素多的条件是 元素数量≥ ceil m/2。\n\n根据上述原理,我使用C语言实现了B树完整的 **增删查** 操作,并增加了 **检验有效性** 、 **打印B树** 的代码,以及 **测试代码(终端显示进度条)** 。同样为了加快开发速度,预设“键值对”的类型为、,后续将B树添加进“kv存储协议”中时会进一步修改:\n\n **btree_int.c** -共989行\n\n\n\n```\n#include \n\n终于度过了本项目所有最难的部分,下面的内容都比较简单。链式哈希的增删查操作简洁明了。链式哈希首先会声明一个固定长度的哈希表(如1024),若需要 **插入新元素时** ,首先计算哈希值作为索引,若有冲突则直接在当前位置使用“ **头插法** ”即可。注意以下几点:\n\n就不单独写型的代码并测试了,可以直接参考\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“hash.h”、“hash.c”。\n\n### 2.6 dhash的实现\n\n
\n\n终于度过了本项目所有最难的部分,下面的内容都比较简单。链式哈希的增删查操作简洁明了。链式哈希首先会声明一个固定长度的哈希表(如1024),若需要 **插入新元素时** ,首先计算哈希值作为索引,若有冲突则直接在当前位置使用“ **头插法** ”即可。注意以下几点:\n\n就不单独写型的代码并测试了,可以直接参考\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“hash.h”、“hash.c”。\n\n### 2.6 dhash的实现\n\n  \n\n显然上述hash有个很大问题,就是“哈希表的大小”是固定的。如果声明哈希表大小为1024,却要插入10w个元素,那每个所有都会对应一个很长的链表,最坏的情况下和直接遍历一遍没什么区别!这显然失去了哈希的意义,于是在上面的基础上,我们使用“空间换时间”,自动增加/缩减哈希表的大小,也就是“动态哈希表”dhash:\n\n同样,不单独写型的代码测试了,可以直接参考\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“dhash.h”、“dhash.c”。\n\n### 2.7 skiplist的实现\n\n
\n\n显然上述hash有个很大问题,就是“哈希表的大小”是固定的。如果声明哈希表大小为1024,却要插入10w个元素,那每个所有都会对应一个很长的链表,最坏的情况下和直接遍历一遍没什么区别!这显然失去了哈希的意义,于是在上面的基础上,我们使用“空间换时间”,自动增加/缩减哈希表的大小,也就是“动态哈希表”dhash:\n\n同样,不单独写型的代码测试了,可以直接参考\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“dhash.h”、“dhash.c”。\n\n### 2.7 skiplist的实现\n\n  \n\n跳表本质上是一个有序链表。红黑树每次比较都能排除一半的节点,这启发我们,要是每次都能找到链表最中间的节点,不就可以实现O ( log N )的查找时间复杂度了嘛。于是如上图所示,我们不妨规定跳表的每个节点都有一组指针,跳表还有一个额外的空节点作为“跳表头”,那么每次都从顶层依次底层进行“跳”,就可以实现“ **每次比较都能排除剩下一半的节点** ”。但是还有个大问题,那就是上述理想跳表需要插入/删除一个元素时,元素的调整会非常麻烦,甚至还需要遍历整个链表来调整所有节点的指向!\n\n所以在实际应用中,不会直接使用上述理想跳表的结构。而是在每次插入一个新元素时, **按照一定概率计算其高度** 。统计学证明,当存放元素足够多的时候,该实际跳表性能无限趋近于理想跳表。\n\n
\n\n跳表本质上是一个有序链表。红黑树每次比较都能排除一半的节点,这启发我们,要是每次都能找到链表最中间的节点,不就可以实现O ( log N )的查找时间复杂度了嘛。于是如上图所示,我们不妨规定跳表的每个节点都有一组指针,跳表还有一个额外的空节点作为“跳表头”,那么每次都从顶层依次底层进行“跳”,就可以实现“ **每次比较都能排除剩下一半的节点** ”。但是还有个大问题,那就是上述理想跳表需要插入/删除一个元素时,元素的调整会非常麻烦,甚至还需要遍历整个链表来调整所有节点的指向!\n\n所以在实际应用中,不会直接使用上述理想跳表的结构。而是在每次插入一个新元素时, **按照一定概率计算其高度** 。统计学证明,当存放元素足够多的时候,该实际跳表性能无限趋近于理想跳表。\n\n  \n\n同样,代码直接见\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“skiplist.h”、“skiplist.c”。\n\n### 2.8 kv存储协议的实现\n\n如“1.2节-项目预期及基本架构”给出的“服务端程序架构”。现在我们实现了网络收发功能(网络层)、所有存储引擎的增删查改操作(引擎层),还差最后一个“kv存储协议”(协议层)就可以实现完整的服务端程序。“kv存储协议”的主要功能有:\n\n值得注意的是,“引擎层”的接口函数应该统一封装命名,并在各存储引擎中实现,“引擎层”的头文件中也只有这些接口函数暴露给“协议层”。这样保证了“协议层”和“引擎层”的隔离性,即使后续“引擎层”代码需要进行修改,也不会干扰到接口函数的调用、无需修改协议层。整个“服务端”的“网络层”、“协议层”、“引擎层”的函数调用关系如下:\n\n
\n\n同样,代码直接见\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“skiplist.h”、“skiplist.c”。\n\n### 2.8 kv存储协议的实现\n\n如“1.2节-项目预期及基本架构”给出的“服务端程序架构”。现在我们实现了网络收发功能(网络层)、所有存储引擎的增删查改操作(引擎层),还差最后一个“kv存储协议”(协议层)就可以实现完整的服务端程序。“kv存储协议”的主要功能有:\n\n值得注意的是,“引擎层”的接口函数应该统一封装命名,并在各存储引擎中实现,“引擎层”的头文件中也只有这些接口函数暴露给“协议层”。这样保证了“协议层”和“引擎层”的隔离性,即使后续“引擎层”代码需要进行修改,也不会干扰到接口函数的调用、无需修改协议层。整个“服务端”的“网络层”、“协议层”、“引擎层”的函数调用关系如下:\n\n  \n\n同样,代码直接见\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“kvstore.h”、“kvstore.c”。\n\n## 3. 性能测试\n\n
\n\n同样,代码直接见\n\n[项目源码](https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1)中的“kvstore.h”、“kvstore.c”。\n\n## 3. 性能测试\n\n  \n\n上述我们将“服务端”的代码实现完毕,并且可以使用“网络连接助手”进行正常的收发数据。如上图所示,依次发送5条指令后都得到预期的回复。但是我们要想测试客户端的极限性能,显然需要写一个“客户端”测试程序。该测试程序目标如下:\n\n如下图所示,开启两个Ubuntu虚拟机,分别运行“服务端”、“客户端”程序,得到如下的测试数据:\n\n
\n\n上述我们将“服务端”的代码实现完毕,并且可以使用“网络连接助手”进行正常的收发数据。如上图所示,依次发送5条指令后都得到预期的回复。但是我们要想测试客户端的极限性能,显然需要写一个“客户端”测试程序。该测试程序目标如下:\n\n如下图所示,开启两个Ubuntu虚拟机,分别运行“服务端”、“客户端”程序,得到如下的测试数据:\n\n  \n\n
\n\n  \n\n **结果分析** :\n\n## 4. 项目总结及改进思路\n\nC/C++适合做服务器,但不适合做业务。因为可能会因为一行代码有问题,导致整个进程退出。虽然也能做,但维护成本高,并且对工程师要求高。比如“腾讯课堂”中课程、图片、价格等参数很适合用C语言做“kv存储”,但是显示网页等业务功能使用Jc语言更加合适。所以 **VUE框架(Java)等适合做前端业务;C/C++适合做基础架构、高性能组件、中间件** 。比如在量化交易中,底层的高频组件、低延迟组件适合用C/C++,上层的交易业务、交易策略没必要C/C++。\n\n C/C++适合做服务器,但不适合做业务。因为可能会因为一行代码有问题,导致整个进程退出。虽然也能做,但维护成本高,并且对工程师要求高。比如“腾讯课堂”中课程、图片、价格等参数很适合用C语言做“kv存储”,但是显示网页等业务功能使用Jc语言更加合适。所以VUE框架(Java)等适合做前端业务;C/C++适合做基础架构、高性能组件、中间件。比如在量化交易中,底层的高频组件、低延迟组件适合用C/C++,上层的交易业务、交易策略没必要C/C++。\n\n **下面是对本项目的一些 改进思路:** \n\n **编程感想:** \n\n1.字符串拷贝:C语言中,使用strncpy、snprintf拷贝字符串时,注意目的字符串不能只是声明为char*,而是需要malloc/calloc分配内存才可以。另外也不要忘了释放内存free。\n\n2.天坑:解析指令时层层传递的是epoll的读缓冲rbuffer,然后使用strtok/strtok_r进行分割指令并存储在char* tokens[]中,注意这个char* tokens[]的元素指向的就是读缓冲本身!!!而snprintf是逐字符进行拷贝的,也就是说,此时使用snprintf将tokens的内容再写回读缓冲就会导致读缓冲错乱。如果不额外分配内存很难解决该问题。所以建议不要使用snprintf拷贝自己的格式化字符串。\n\n3.良好的内存管理习惯:free()之前先判断是否为NULL,free()之后一定要指向NULL。\n\n4.层层传递初始化:\n\n【可行方法1】如果最顶层需要创建实例对象(不如全局变量),那就需要传地址给最底层,且最底层无需再重新为这个对象malloc空间(因为最顶层已经创建对象了),只需要malloc好这个实例对象的所有指针即可,或者先定义成NULL后期插入时再分配。\n\n【可行方法2】若最顶层无需创建全局的实例对象,那么也可以不传参数给最底层,最底层直接创建一个对象指针,并malloc/NULL这个对象指针的所有参数,最后直接返回这个对象指针就行。\n\n【不可行方法】顶层创建了全局的实例对象,然后传地址给最底层,最底层重新malloc一个新的对象指针,初始化这个对象指针的所有参数,最后让传递下来的地址指向这个指针。最后在顶层就会发现所有参数都没初始化,都是空!\n\n【关键点】:对谁进行malloc非常重要,一定要对顶层传下来的结构体指针的元素直接malloc,而不是malloc一个新的结构体,在赋值给这个结构体指针。\n\n5.关于strcmp():在使用strcmp()时一定要先判断不为空,才能使用。这是因为strcmp()的底层使用while(*des++==*src**),所以若比较的双方有一方为空,就会直接报错。\n\n6.注意项目的include关系,是在编译指令中指定的。当然也可以将“kv_store.c”中的case语句封装到各自的数据结构中,然后以动态库的方式进行编译。\n\n链接:\n\n[基于C语言实现内存型数据库(kv存储)](https://blog.csdn.net/weixin_46258766/article/details/136228729)\n\n
\n\n **结果分析** :\n\n## 4. 项目总结及改进思路\n\nC/C++适合做服务器,但不适合做业务。因为可能会因为一行代码有问题,导致整个进程退出。虽然也能做,但维护成本高,并且对工程师要求高。比如“腾讯课堂”中课程、图片、价格等参数很适合用C语言做“kv存储”,但是显示网页等业务功能使用Jc语言更加合适。所以 **VUE框架(Java)等适合做前端业务;C/C++适合做基础架构、高性能组件、中间件** 。比如在量化交易中,底层的高频组件、低延迟组件适合用C/C++,上层的交易业务、交易策略没必要C/C++。\n\n C/C++适合做服务器,但不适合做业务。因为可能会因为一行代码有问题,导致整个进程退出。虽然也能做,但维护成本高,并且对工程师要求高。比如“腾讯课堂”中课程、图片、价格等参数很适合用C语言做“kv存储”,但是显示网页等业务功能使用Jc语言更加合适。所以VUE框架(Java)等适合做前端业务;C/C++适合做基础架构、高性能组件、中间件。比如在量化交易中,底层的高频组件、低延迟组件适合用C/C++,上层的交易业务、交易策略没必要C/C++。\n\n **下面是对本项目的一些 改进思路:** \n\n **编程感想:** \n\n1.字符串拷贝:C语言中,使用strncpy、snprintf拷贝字符串时,注意目的字符串不能只是声明为char*,而是需要malloc/calloc分配内存才可以。另外也不要忘了释放内存free。\n\n2.天坑:解析指令时层层传递的是epoll的读缓冲rbuffer,然后使用strtok/strtok_r进行分割指令并存储在char* tokens[]中,注意这个char* tokens[]的元素指向的就是读缓冲本身!!!而snprintf是逐字符进行拷贝的,也就是说,此时使用snprintf将tokens的内容再写回读缓冲就会导致读缓冲错乱。如果不额外分配内存很难解决该问题。所以建议不要使用snprintf拷贝自己的格式化字符串。\n\n3.良好的内存管理习惯:free()之前先判断是否为NULL,free()之后一定要指向NULL。\n\n4.层层传递初始化:\n\n【可行方法1】如果最顶层需要创建实例对象(不如全局变量),那就需要传地址给最底层,且最底层无需再重新为这个对象malloc空间(因为最顶层已经创建对象了),只需要malloc好这个实例对象的所有指针即可,或者先定义成NULL后期插入时再分配。\n\n【可行方法2】若最顶层无需创建全局的实例对象,那么也可以不传参数给最底层,最底层直接创建一个对象指针,并malloc/NULL这个对象指针的所有参数,最后直接返回这个对象指针就行。\n\n【不可行方法】顶层创建了全局的实例对象,然后传地址给最底层,最底层重新malloc一个新的对象指针,初始化这个对象指针的所有参数,最后让传递下来的地址指向这个指针。最后在顶层就会发现所有参数都没初始化,都是空!\n\n【关键点】:对谁进行malloc非常重要,一定要对顶层传下来的结构体指针的元素直接malloc,而不是malloc一个新的结构体,在赋值给这个结构体指针。\n\n5.关于strcmp():在使用strcmp()时一定要先判断不为空,才能使用。这是因为strcmp()的底层使用while(*des++==*src**),所以若比较的双方有一方为空,就会直接报错。\n\n6.注意项目的include关系,是在编译指令中指定的。当然也可以将“kv_store.c”中的case语句封装到各自的数据结构中,然后以动态库的方式进行编译。\n\n链接:\n\n[基于C语言实现内存型数据库(kv存储)](https://blog.csdn.net/weixin_46258766/article/details/136228729)\n\n\n\n[https://zhuanlan.zhihu.com/p/700085445](https://zhuanlan.zhihu.com/p/700085445)
\n -->

关于博主
an actually real engineer
通信工程专业毕业,7年开发经验
技术栈:
精通c/c++
精通golang
熟悉常见的脚本,js,lua,python,php
熟悉电路基础,嵌入式,单片机
耕耘领域:
服务端开发
嵌入式开发
>gin接口代码CURD生成工具
sql ddl to struct and markdown,将sql表自动化生成代码内对应的结构体和markdown表格格式,节省宝贵的时间。
qt .ui文件转css文件
duilib xml 自动生成绑定控件代码
协议调试器
基于lua虚拟机的的协议调试器软件 支持的协议有:
串口
tcp客户端/服务端
udp 组播/udp节点
tcp websocket 客户端/服务端
软件界面

使用例子: 通过脚本来获得接收到的数据并写入文件和展示在界面上
下载地址和源码
webrtc easy demo
webrtc c++ native 库 demo 实现功能:
基于QT
webrtc摄像头/桌面捕获功能
opengl渲染/多播放窗格管理
janus meeting room
下载地址和源码
wifi,蓝牙 - 无线开关
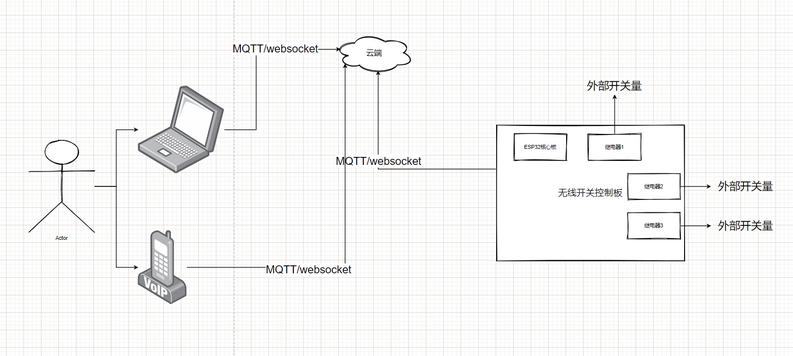
实现功能:
通过wifi/蓝牙实现远程开关电器或者其他电子设备
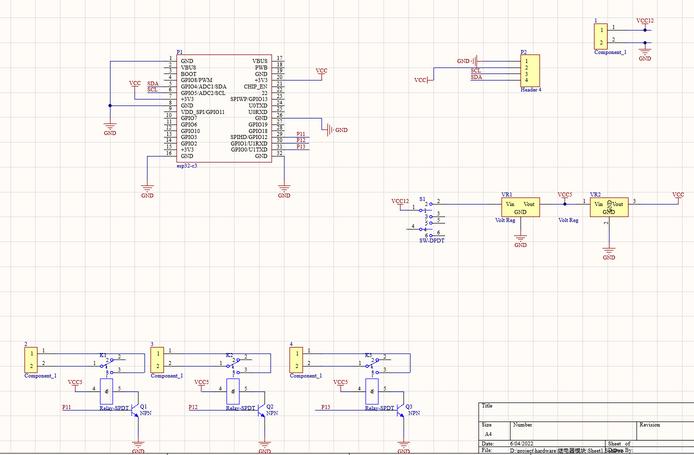
电路原理图:
实物图:

深度学习验证工具
虚拟示波器
硬件实物图:

实现原理
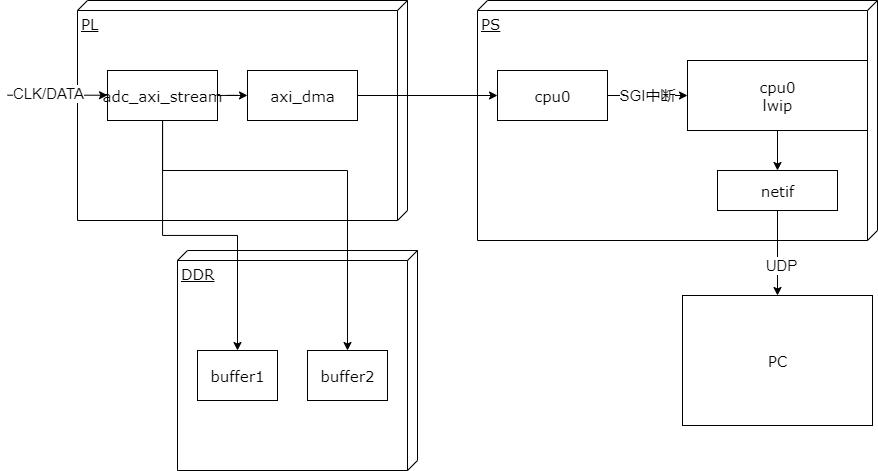
基本性能
采集频率: 取决于外部adc模块和ebaz4205矿板的以太网接口速率,最高可以达到100M/8 约为12.5MPS
上位机实现功能: 采集,显示波形,存储wave文件。
参数可运行时配置
上位机:

显示缓冲区大小可调
刷新率可调节
触发显示刷新可调节

又一个modbus调试工具
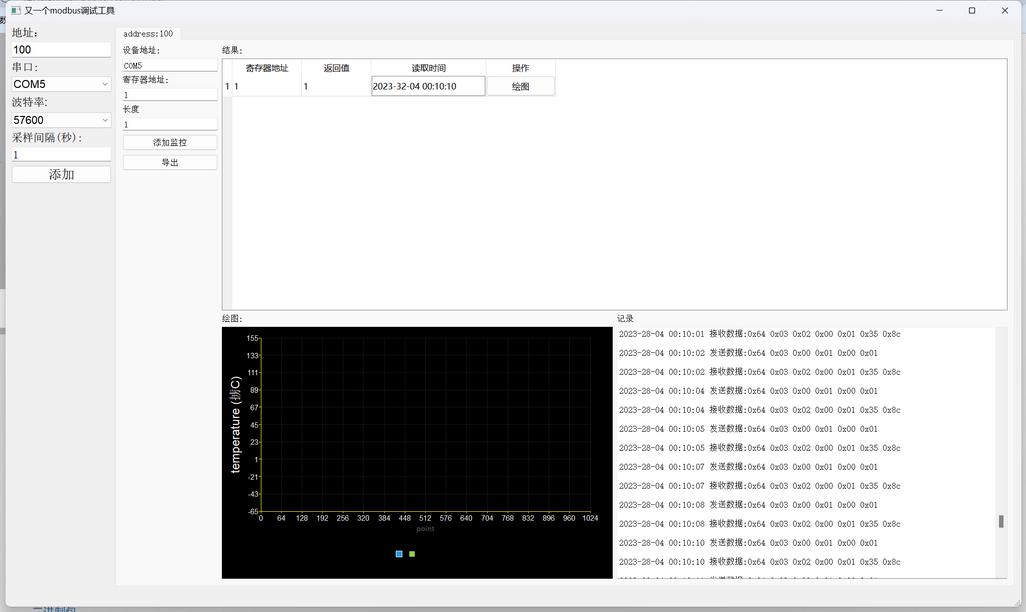
最近混迹物联网企业,发现目前缺少一个简易可用的modbus调试工具,本软件旨在为开发者提供一个简单modbus测试工具。 主打一个代码简单易修改。 特点:
1. 基于QT5
2. 基于libmodbus
3. 三方库完全跨平台,linux/windows。
开源plutosdr 板卡

1. 完全开源
2. 提高固件定制服务
3. 硬件售价450 手焊产量有线
测试数据
内部DDS回环测试

接收测试
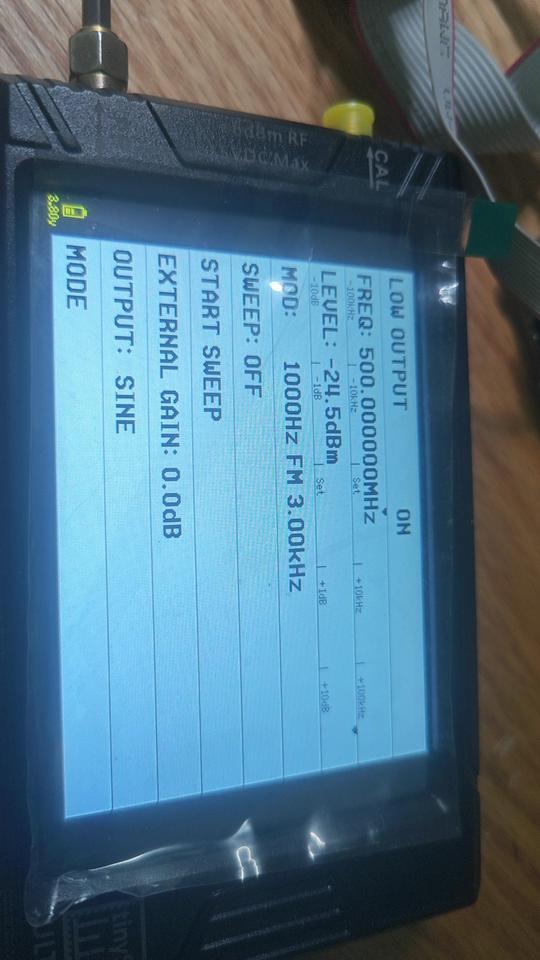
外部发送500MHZ FM波形
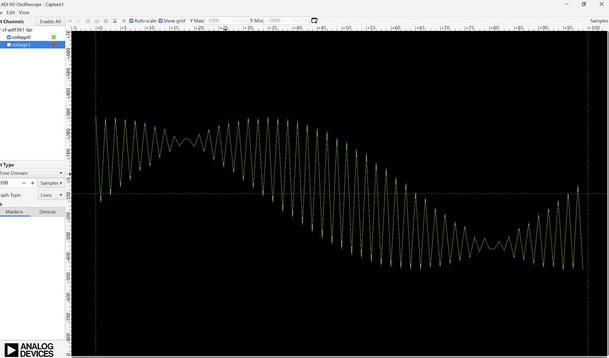
matlab测试

2TRX版本

大部分plutosdr应用场景都是讲plutosdr板卡作为射频收发器来使用。 实际上plutosdr板卡本身运行linux 操作系统。是具有一定脱机运算的能力。 对于一些微型频谱检测,简单射频信号收发等应用完全可以将应用层直接实现在板卡上 相较于通过网卡或者USB口传输具有更稳定,带宽更高等优点。 本开源板卡由于了SD卡启动,较原版pluto支持了自定义启动应用的功能。 提供了应用层开发SDK(编译器,buildroot文件系统)。 通过usb连接电脑,经过RNDIS驱动可以近似为通过网卡连接 (支持固件的开发定制)。
二次开发例子
``` all: arm-linux-gnueabihf-gcc -mfloat-abi=hard --sysroot=/root/v0.32_2trx/buildroot/output/staging -std=gnu99 -g -o pluto_stream ad9361-iiostream.c -lpthread -liio -lm -Wall -Wextra -lrt clean: rm pluto_stream
版面分析即分析出图片内的具体文件元素,如文档标题,文档内容,文档页码等,本工具基于cnstd模型