 \n\nFig. Netfilter 中的连接跟踪点\n\n如上图所示,Netfilter 在四个 Hook 点对包进行跟踪:\n\n1. 和 : **调用 nf_conntrack_in() 开始连接跟踪** , 正常情况下会创建一条新连接记录,然后将 conntrack entry 放到 **unconfirmed list** 。\n为什么是这两个 hook 点呢?因为它们都是 **新连接的第一个包最先达到的地方** ,\n\n2. 和 : **调用 nf_conntrack_confirm() 将 nf_conntrack_in() 创建的连接移到 confirmed list** 。\n同样要问,为什么在这两个 hook 点呢?因为如果新连接的第一个包没有被丢弃,那这 是它们 **离开 netfilter 之前的最后 hook 点** :\n\n下面的代码可以看到 **这些 handler 是如何注册到 Netfilter hook 点的** :\n\n\n\n```\n// net/netfilter/nf_conntrack_proto.c\n \n/* Connection tracking may drop packets, but never alters them, so make it the first hook. */\nstatic const struct nf_hook_ops ipv4_conntrack_ops[] = {\n {\n .hook = ipv4_conntrack_in, // 调用 nf_conntrack_in() 进入连接跟踪\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_PRE_ROUTING, // PRE_ROUTING hook 点\n .priority = NF_IP_PRI_CONNTRACK,\n },\n {\n .hook = ipv4_conntrack_local, // 调用 nf_conntrack_in() 进入连接跟踪\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_LOCAL_OUT, // LOCAL_OUT hook 点\n .priority = NF_IP_PRI_CONNTRACK,\n },\n {\n .hook = ipv4_confirm, // 调用 nf_conntrack_confirm()\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_POST_ROUTING, // POST_ROUTING hook 点\n .priority = NF_IP_PRI_CONNTRACK_CONFIRM,\n },\n {\n .hook = ipv4_confirm, // 调用 nf_conntrack_confirm()\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_LOCAL_IN, // LOCAL_IN hook 点\n .priority = NF_IP_PRI_CONNTRACK_CONFIRM,\n },\n};\n```\n\n 是 **连接跟踪模块的核心** 。\n\n\n\n```\n// net/netfilter/nf_conntrack_core.c\n \nunsigned int\nnf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum, struct sk_buff *skb)\n{\n struct nf_conn *tmpl = nf_ct_get(skb, &ctinfo); // 获取 skb 对应的 conntrack_info 和连接记录\n if (tmpl || ctinfo == IP_CT_UNTRACKED) { // 如果记录存在,或者是不需要跟踪的类型\n if ((tmpl && !nf_ct_is_template(tmpl)) || ctinfo == IP_CT_UNTRACKED) {\n NF_CT_STAT_INC_ATOMIC(net, ignore); // 无需跟踪的类型,增加 ignore 计数\n return NF_ACCEPT; // 返回 NF_ACCEPT,继续后面的处理\n }\n skb->_nfct = 0; // 不属于 ignore 类型,计数器置零,准备后续处理\n }\n \n struct nf_conntrack_l4proto *l4proto = __nf_ct_l4proto_find(...); // 提取协议相关的 L4 头信息\n \n if (l4proto->error != NULL) { // skb 的完整性和合法性验证\n if (l4proto->error(net, tmpl, skb, dataoff, pf, hooknum) <= 0) {\n NF_CT_STAT_INC_ATOMIC(net, error);\n NF_CT_STAT_INC_ATOMIC(net, invalid);\n goto out;\n }\n }\n \nrepeat:\n // 开始连接跟踪:提取 tuple;创建新连接记录,或者更新已有连接的状态\n resolve_normal_ct(net, tmpl, skb, ... l4proto);\n \n l4proto->packet(ct, skb, dataoff, ctinfo); // 进行一些协议相关的处理,例如 UDP 会更新 timeout\n \n if (ctinfo == IP_CT_ESTABLISHED_REPLY && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))\n nf_conntrack_event_cache(IPCT_REPLY, ct);\nout:\n if (tmpl)\n nf_ct_put(tmpl); // 解除对连接记录 tmpl 的引用\n}\n```\n\n大致流程:\n\n### 3.7 :创建新连接记录\n\n如果连接不存在(flow 的第一个包), 会调用 ,后者进而会调用 方法创建一个新的 conntrack entry。\n\n\n\n```\n// include/net/netfilter/nf_conntrack_core.c\n \n// Allocate a new conntrack\nstatic noinline struct nf_conntrack_tuple_hash *\ninit_conntrack(struct net *net, struct nf_conn *tmpl,\n const struct nf_conntrack_tuple *tuple,\n const struct nf_conntrack_l4proto *l4proto,\n struct sk_buff *skb, unsigned int dataoff, u32 hash)\n{\n struct nf_conn *ct;\n \n // 从 conntrack table 中分配一个 entry,如果哈希表满了,会在内核日志中打印\n // \"nf_conntrack: table full, dropping packet\" 信息,通过 `dmesg -T` 能看到\n ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC, hash);\n \n l4proto->new(ct, skb, dataoff); // 协议相关的方法\n \n local_bh_disable(); // 关闭软中断\n if (net->ct.expect_count) {\n exp = nf_ct_find_expectation(net, zone, tuple);\n if (exp) {\n /* Welcome, Mr. Bond. We\'ve been expecting you... */\n __set_bit(IPS_EXPECTED_BIT, &ct->status);\n \n /* exp->master safe, refcnt bumped in nf_ct_find_expectation */\n ct->master = exp->master;\n ct->mark = exp->master->mark;\n ct->secmark = exp->master->secmark;\n NF_CT_STAT_INC(net, expect_new);\n }\n }\n \n /* Now it is inserted into the unconfirmed list, bump refcount */\n // 至此这个新的 conntrack entry 已经被插入 unconfirmed list\n nf_conntrack_get(&ct->ct_general);\n nf_ct_add_to_unconfirmed_list(ct);\n \n local_bh_enable(); // 重新打开软中断\n \n if (exp) {\n if (exp->expectfn)\n exp->expectfn(ct, exp);\n nf_ct_expect_put(exp);\n }\n \n return &ct->tuplehash[IP_CT_DIR_ORIGINAL];\n}\n```\n\n每种协议需要实现自己的 方法,代码见:。 例如 TCP 协议对应的 方法是:\n\n\n\n```\n// net/netfilter/nf_conntrack_proto_tcp.c\n \n/* Called when a new connection for this protocol found. */\nstatic bool tcp_new(struct nf_conn *ct, const struct sk_buff *skb, unsigned int dataoff)\n{\n if (new_state == TCP_CONNTRACK_SYN_SENT) {\n memset(&ct->proto.tcp, 0, sizeof(ct->proto.tcp));\n /* SYN packet */\n ct->proto.tcp.seen[0].td_end = segment_seq_plus_len(ntohl(th->seq), skb->len, dataoff, th);\n ct->proto.tcp.seen[0].td_maxwin = ntohs(th->window);\n ...\n}\n```\n\n如果当前包会影响后面包的状态判断, 会设置 的 字段。面向连接的协议会用到这个特性,例如 TCP。\n\n### 3.8 :确认包没有被丢弃\n\n 创建的新 conntrack entry 会插入到一个 **未确认连接** ( unconfirmed connection)列表。\n\n如果这个包之后没有被丢弃,那它在经过 时会被 方法处理,原理我们在分析过了 3.6 节的开头分析过了。 完成之后,状态就变为了 ,并且连接记录从 **未确认列表** 移到 **正常** 的列表。\n\n之所以把创建一个新 entry 的过程分为创建(new)和确认(confirm)两个阶段 ,是因为 **包在经过 nf_conntrack_in() 之后,到达 nf_conntrack_confirm() 之前 ,可能会被内核丢弃** 。这样会导致系统残留大量的半连接状态记录,在性能和安全性上都 是很大问题。分为两步之后,可以加快半连接状态 conntrack entry 的 GC。\n\n\n\n```\n// include/net/netfilter/nf_conntrack_core.h\n \n/* Confirm a connection: returns NF_DROP if packet must be dropped. */\nstatic inline int nf_conntrack_confirm(struct sk_buff *skb)\n{\n struct nf_conn *ct = (struct nf_conn *)skb_nfct(skb);\n int ret = NF_ACCEPT;\n \n if (ct) {\n if (!nf_ct_is_confirmed(ct))\n ret = __nf_conntrack_confirm(skb);\n if (likely(ret == NF_ACCEPT))\n nf_ct_deliver_cached_events(ct);\n }\n return ret;\n}\n```\n\nconfirm 逻辑,省略了各种错误处理逻辑:\n\n\n\n```\n// net/netfilter/nf_conntrack_core.c\n \n/* Confirm a connection given skb; places it in hash table */\nint\n__nf_conntrack_confirm(struct sk_buff *skb)\n{\n struct nf_conn *ct;\n ct = nf_ct_get(skb, &ctinfo);\n \n local_bh_disable(); // 关闭软中断\n \n hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;\n reply_hash = hash_conntrack(net, &ct->tuplehash[IP_CT_DIR_REPLY].tuple);\n \n ct->timeout += nfct_time_stamp; // 更新连接超时时间,超时后会被 GC\n atomic_inc(&ct->ct_general.use); // 设置连接引用计数?\n ct->status |= IPS_CONFIRMED; // 设置连接状态为 confirmed\n \n __nf_conntrack_hash_insert(ct, hash, reply_hash); // 插入到连接跟踪哈希表\n \n local_bh_enable(); // 重新打开软中断\n \n nf_conntrack_event_cache(master_ct(ct) ? IPCT_RELATED : IPCT_NEW, ct);\n return NF_ACCEPT;\n}\n```\n\n可以看到, **连接跟踪的处理逻辑中需要频繁关闭和打开软中断** ,此外还有各种锁, 这是短连高并发场景下连接跟踪性能损耗的主要原因?。\n\n## 4 Netfilter NAT 实现\n\nNAT 是与连接跟踪独立的模块。\n\n### 4.1 重要数据结构和函数\n\n **重要数据结构:** \n\n支持 NAT 的协议需要实现其中的方法:\n\n **重要函数:** \n\n### 4.2 NAT 模块初始化\n\n\n\n```\n// net/netfilter/nf_nat_core.c\n \nstatic struct nf_nat_hook nat_hook = {\n .parse_nat_setup = nfnetlink_parse_nat_setup,\n .decode_session = __nf_nat_decode_session,\n .manip_pkt = nf_nat_manip_pkt,\n};\n \nstatic int __init nf_nat_init(void)\n{\n nf_nat_bysource = nf_ct_alloc_hashtable(&nf_nat_htable_size, 0);\n \n nf_ct_helper_expectfn_register(&follow_master_nat);\n \n RCU_INIT_POINTER(nf_nat_hook, &nat_hook);\n}\n \nMODULE_LICENSE(\"GPL\");\nmodule_init(nf_nat_init);\n```\n\n### 4.3 :协议相关的 NAT 方法集\n\n\n\n```\n// include/net/netfilter/nf_nat_l3proto.h\n \nstruct nf_nat_l3proto {\n u8 l3proto; // 例如,AF_INET\n \n u32 (*secure_port )(const struct nf_conntrack_tuple *t, __be16);\n bool (*manip_pkt )(struct sk_buff *skb, ...);\n void (*csum_update )(struct sk_buff *skb, ...);\n void (*csum_recalc )(struct sk_buff *skb, u8 proto, ...);\n void (*decode_session )(struct sk_buff *skb, ...);\n int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);\n};\n```\n\n## 4.4 :协议相关的 NAT 方法集\n\n\n\n```\n// include/net/netfilter/nf_nat_l4proto.h\n \nstruct nf_nat_l4proto {\n u8 l4proto; // Protocol number,例如 IPPROTO_UDP, IPPROTO_TCP\n \n // 根据传入的 tuple 和 NAT 类型(SNAT/DNAT)修改包的 L3/L4 头\n bool (*manip_pkt)(struct sk_buff *skb, *l3proto, *tuple, maniptype);\n \n // 创建一个唯一的 tuple\n // 例如对于 UDP,会根据 src_ip, dst_ip, src_port 加一个随机数生成一个 16bit 的 dst_port\n void (*unique_tuple)(*l3proto, tuple, struct nf_nat_range2 *range, maniptype, struct nf_conn *ct);\n \n // If the address range is exhausted the NAT modules will begin to drop packets.\n int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);\n};\n```\n\n各协议实现的方法,见:。例如 TCP 的实现:\n\n\n\n```\n// net/netfilter/nf_nat_proto_tcp.c\n \nconst struct nf_nat_l4proto nf_nat_l4proto_tcp = {\n .l4proto = IPPROTO_TCP,\n .manip_pkt = tcp_manip_pkt,\n .in_range = nf_nat_l4proto_in_range,\n .unique_tuple = tcp_unique_tuple,\n .nlattr_to_range = nf_nat_l4proto_nlattr_to_range,\n};\n```\n\n### 4.5 :进入 NAT\n\nNAT 的核心函数是 ,它会在以下 hook 点被调用:\n\n也就是除了 之外其他 hook 点都会被调用。\n\n **在这些 hook 点的优先级** : **Conntrack > NAT > Packet Filtering** 。 **连接跟踪的优先级高于 NAT** 是因为 NAT 依赖连接跟踪的结果。\n\n
\n\nFig. Netfilter 中的连接跟踪点\n\n如上图所示,Netfilter 在四个 Hook 点对包进行跟踪:\n\n1. 和 : **调用 nf_conntrack_in() 开始连接跟踪** , 正常情况下会创建一条新连接记录,然后将 conntrack entry 放到 **unconfirmed list** 。\n为什么是这两个 hook 点呢?因为它们都是 **新连接的第一个包最先达到的地方** ,\n\n2. 和 : **调用 nf_conntrack_confirm() 将 nf_conntrack_in() 创建的连接移到 confirmed list** 。\n同样要问,为什么在这两个 hook 点呢?因为如果新连接的第一个包没有被丢弃,那这 是它们 **离开 netfilter 之前的最后 hook 点** :\n\n下面的代码可以看到 **这些 handler 是如何注册到 Netfilter hook 点的** :\n\n\n\n```\n// net/netfilter/nf_conntrack_proto.c\n \n/* Connection tracking may drop packets, but never alters them, so make it the first hook. */\nstatic const struct nf_hook_ops ipv4_conntrack_ops[] = {\n {\n .hook = ipv4_conntrack_in, // 调用 nf_conntrack_in() 进入连接跟踪\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_PRE_ROUTING, // PRE_ROUTING hook 点\n .priority = NF_IP_PRI_CONNTRACK,\n },\n {\n .hook = ipv4_conntrack_local, // 调用 nf_conntrack_in() 进入连接跟踪\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_LOCAL_OUT, // LOCAL_OUT hook 点\n .priority = NF_IP_PRI_CONNTRACK,\n },\n {\n .hook = ipv4_confirm, // 调用 nf_conntrack_confirm()\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_POST_ROUTING, // POST_ROUTING hook 点\n .priority = NF_IP_PRI_CONNTRACK_CONFIRM,\n },\n {\n .hook = ipv4_confirm, // 调用 nf_conntrack_confirm()\n .pf = NFPROTO_IPV4,\n .hooknum = NF_INET_LOCAL_IN, // LOCAL_IN hook 点\n .priority = NF_IP_PRI_CONNTRACK_CONFIRM,\n },\n};\n```\n\n 是 **连接跟踪模块的核心** 。\n\n\n\n```\n// net/netfilter/nf_conntrack_core.c\n \nunsigned int\nnf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum, struct sk_buff *skb)\n{\n struct nf_conn *tmpl = nf_ct_get(skb, &ctinfo); // 获取 skb 对应的 conntrack_info 和连接记录\n if (tmpl || ctinfo == IP_CT_UNTRACKED) { // 如果记录存在,或者是不需要跟踪的类型\n if ((tmpl && !nf_ct_is_template(tmpl)) || ctinfo == IP_CT_UNTRACKED) {\n NF_CT_STAT_INC_ATOMIC(net, ignore); // 无需跟踪的类型,增加 ignore 计数\n return NF_ACCEPT; // 返回 NF_ACCEPT,继续后面的处理\n }\n skb->_nfct = 0; // 不属于 ignore 类型,计数器置零,准备后续处理\n }\n \n struct nf_conntrack_l4proto *l4proto = __nf_ct_l4proto_find(...); // 提取协议相关的 L4 头信息\n \n if (l4proto->error != NULL) { // skb 的完整性和合法性验证\n if (l4proto->error(net, tmpl, skb, dataoff, pf, hooknum) <= 0) {\n NF_CT_STAT_INC_ATOMIC(net, error);\n NF_CT_STAT_INC_ATOMIC(net, invalid);\n goto out;\n }\n }\n \nrepeat:\n // 开始连接跟踪:提取 tuple;创建新连接记录,或者更新已有连接的状态\n resolve_normal_ct(net, tmpl, skb, ... l4proto);\n \n l4proto->packet(ct, skb, dataoff, ctinfo); // 进行一些协议相关的处理,例如 UDP 会更新 timeout\n \n if (ctinfo == IP_CT_ESTABLISHED_REPLY && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))\n nf_conntrack_event_cache(IPCT_REPLY, ct);\nout:\n if (tmpl)\n nf_ct_put(tmpl); // 解除对连接记录 tmpl 的引用\n}\n```\n\n大致流程:\n\n### 3.7 :创建新连接记录\n\n如果连接不存在(flow 的第一个包), 会调用 ,后者进而会调用 方法创建一个新的 conntrack entry。\n\n\n\n```\n// include/net/netfilter/nf_conntrack_core.c\n \n// Allocate a new conntrack\nstatic noinline struct nf_conntrack_tuple_hash *\ninit_conntrack(struct net *net, struct nf_conn *tmpl,\n const struct nf_conntrack_tuple *tuple,\n const struct nf_conntrack_l4proto *l4proto,\n struct sk_buff *skb, unsigned int dataoff, u32 hash)\n{\n struct nf_conn *ct;\n \n // 从 conntrack table 中分配一个 entry,如果哈希表满了,会在内核日志中打印\n // \"nf_conntrack: table full, dropping packet\" 信息,通过 `dmesg -T` 能看到\n ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC, hash);\n \n l4proto->new(ct, skb, dataoff); // 协议相关的方法\n \n local_bh_disable(); // 关闭软中断\n if (net->ct.expect_count) {\n exp = nf_ct_find_expectation(net, zone, tuple);\n if (exp) {\n /* Welcome, Mr. Bond. We\'ve been expecting you... */\n __set_bit(IPS_EXPECTED_BIT, &ct->status);\n \n /* exp->master safe, refcnt bumped in nf_ct_find_expectation */\n ct->master = exp->master;\n ct->mark = exp->master->mark;\n ct->secmark = exp->master->secmark;\n NF_CT_STAT_INC(net, expect_new);\n }\n }\n \n /* Now it is inserted into the unconfirmed list, bump refcount */\n // 至此这个新的 conntrack entry 已经被插入 unconfirmed list\n nf_conntrack_get(&ct->ct_general);\n nf_ct_add_to_unconfirmed_list(ct);\n \n local_bh_enable(); // 重新打开软中断\n \n if (exp) {\n if (exp->expectfn)\n exp->expectfn(ct, exp);\n nf_ct_expect_put(exp);\n }\n \n return &ct->tuplehash[IP_CT_DIR_ORIGINAL];\n}\n```\n\n每种协议需要实现自己的 方法,代码见:。 例如 TCP 协议对应的 方法是:\n\n\n\n```\n// net/netfilter/nf_conntrack_proto_tcp.c\n \n/* Called when a new connection for this protocol found. */\nstatic bool tcp_new(struct nf_conn *ct, const struct sk_buff *skb, unsigned int dataoff)\n{\n if (new_state == TCP_CONNTRACK_SYN_SENT) {\n memset(&ct->proto.tcp, 0, sizeof(ct->proto.tcp));\n /* SYN packet */\n ct->proto.tcp.seen[0].td_end = segment_seq_plus_len(ntohl(th->seq), skb->len, dataoff, th);\n ct->proto.tcp.seen[0].td_maxwin = ntohs(th->window);\n ...\n}\n```\n\n如果当前包会影响后面包的状态判断, 会设置 的 字段。面向连接的协议会用到这个特性,例如 TCP。\n\n### 3.8 :确认包没有被丢弃\n\n 创建的新 conntrack entry 会插入到一个 **未确认连接** ( unconfirmed connection)列表。\n\n如果这个包之后没有被丢弃,那它在经过 时会被 方法处理,原理我们在分析过了 3.6 节的开头分析过了。 完成之后,状态就变为了 ,并且连接记录从 **未确认列表** 移到 **正常** 的列表。\n\n之所以把创建一个新 entry 的过程分为创建(new)和确认(confirm)两个阶段 ,是因为 **包在经过 nf_conntrack_in() 之后,到达 nf_conntrack_confirm() 之前 ,可能会被内核丢弃** 。这样会导致系统残留大量的半连接状态记录,在性能和安全性上都 是很大问题。分为两步之后,可以加快半连接状态 conntrack entry 的 GC。\n\n\n\n```\n// include/net/netfilter/nf_conntrack_core.h\n \n/* Confirm a connection: returns NF_DROP if packet must be dropped. */\nstatic inline int nf_conntrack_confirm(struct sk_buff *skb)\n{\n struct nf_conn *ct = (struct nf_conn *)skb_nfct(skb);\n int ret = NF_ACCEPT;\n \n if (ct) {\n if (!nf_ct_is_confirmed(ct))\n ret = __nf_conntrack_confirm(skb);\n if (likely(ret == NF_ACCEPT))\n nf_ct_deliver_cached_events(ct);\n }\n return ret;\n}\n```\n\nconfirm 逻辑,省略了各种错误处理逻辑:\n\n\n\n```\n// net/netfilter/nf_conntrack_core.c\n \n/* Confirm a connection given skb; places it in hash table */\nint\n__nf_conntrack_confirm(struct sk_buff *skb)\n{\n struct nf_conn *ct;\n ct = nf_ct_get(skb, &ctinfo);\n \n local_bh_disable(); // 关闭软中断\n \n hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;\n reply_hash = hash_conntrack(net, &ct->tuplehash[IP_CT_DIR_REPLY].tuple);\n \n ct->timeout += nfct_time_stamp; // 更新连接超时时间,超时后会被 GC\n atomic_inc(&ct->ct_general.use); // 设置连接引用计数?\n ct->status |= IPS_CONFIRMED; // 设置连接状态为 confirmed\n \n __nf_conntrack_hash_insert(ct, hash, reply_hash); // 插入到连接跟踪哈希表\n \n local_bh_enable(); // 重新打开软中断\n \n nf_conntrack_event_cache(master_ct(ct) ? IPCT_RELATED : IPCT_NEW, ct);\n return NF_ACCEPT;\n}\n```\n\n可以看到, **连接跟踪的处理逻辑中需要频繁关闭和打开软中断** ,此外还有各种锁, 这是短连高并发场景下连接跟踪性能损耗的主要原因?。\n\n## 4 Netfilter NAT 实现\n\nNAT 是与连接跟踪独立的模块。\n\n### 4.1 重要数据结构和函数\n\n **重要数据结构:** \n\n支持 NAT 的协议需要实现其中的方法:\n\n **重要函数:** \n\n### 4.2 NAT 模块初始化\n\n\n\n```\n// net/netfilter/nf_nat_core.c\n \nstatic struct nf_nat_hook nat_hook = {\n .parse_nat_setup = nfnetlink_parse_nat_setup,\n .decode_session = __nf_nat_decode_session,\n .manip_pkt = nf_nat_manip_pkt,\n};\n \nstatic int __init nf_nat_init(void)\n{\n nf_nat_bysource = nf_ct_alloc_hashtable(&nf_nat_htable_size, 0);\n \n nf_ct_helper_expectfn_register(&follow_master_nat);\n \n RCU_INIT_POINTER(nf_nat_hook, &nat_hook);\n}\n \nMODULE_LICENSE(\"GPL\");\nmodule_init(nf_nat_init);\n```\n\n### 4.3 :协议相关的 NAT 方法集\n\n\n\n```\n// include/net/netfilter/nf_nat_l3proto.h\n \nstruct nf_nat_l3proto {\n u8 l3proto; // 例如,AF_INET\n \n u32 (*secure_port )(const struct nf_conntrack_tuple *t, __be16);\n bool (*manip_pkt )(struct sk_buff *skb, ...);\n void (*csum_update )(struct sk_buff *skb, ...);\n void (*csum_recalc )(struct sk_buff *skb, u8 proto, ...);\n void (*decode_session )(struct sk_buff *skb, ...);\n int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);\n};\n```\n\n## 4.4 :协议相关的 NAT 方法集\n\n\n\n```\n// include/net/netfilter/nf_nat_l4proto.h\n \nstruct nf_nat_l4proto {\n u8 l4proto; // Protocol number,例如 IPPROTO_UDP, IPPROTO_TCP\n \n // 根据传入的 tuple 和 NAT 类型(SNAT/DNAT)修改包的 L3/L4 头\n bool (*manip_pkt)(struct sk_buff *skb, *l3proto, *tuple, maniptype);\n \n // 创建一个唯一的 tuple\n // 例如对于 UDP,会根据 src_ip, dst_ip, src_port 加一个随机数生成一个 16bit 的 dst_port\n void (*unique_tuple)(*l3proto, tuple, struct nf_nat_range2 *range, maniptype, struct nf_conn *ct);\n \n // If the address range is exhausted the NAT modules will begin to drop packets.\n int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);\n};\n```\n\n各协议实现的方法,见:。例如 TCP 的实现:\n\n\n\n```\n// net/netfilter/nf_nat_proto_tcp.c\n \nconst struct nf_nat_l4proto nf_nat_l4proto_tcp = {\n .l4proto = IPPROTO_TCP,\n .manip_pkt = tcp_manip_pkt,\n .in_range = nf_nat_l4proto_in_range,\n .unique_tuple = tcp_unique_tuple,\n .nlattr_to_range = nf_nat_l4proto_nlattr_to_range,\n};\n```\n\n### 4.5 :进入 NAT\n\nNAT 的核心函数是 ,它会在以下 hook 点被调用:\n\n也就是除了 之外其他 hook 点都会被调用。\n\n **在这些 hook 点的优先级** : **Conntrack > NAT > Packet Filtering** 。 **连接跟踪的优先级高于 NAT** 是因为 NAT 依赖连接跟踪的结果。\n\n  \n\nFig. NAT\n\n\n\n```\nunsigned int\nnf_nat_inet_fn(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)\n{\n ct = nf_ct_get(skb, &ctinfo);\n if (!ct) // conntrack 不存在就做不了 NAT,直接返回,这也是我们为什么说 NAT 依赖 conntrack 的结果\n return NF_ACCEPT;\n \n nat = nfct_nat(ct);\n \n switch (ctinfo) {\n case IP_CT_RELATED:\n case IP_CT_RELATED_REPLY: /* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */\n case IP_CT_NEW: /* Seen it before? This can happen for loopback, retrans, or local packets. */\n if (!nf_nat_initialized(ct, maniptype)) {\n struct nf_hook_entries *e = rcu_dereference(lpriv->entries); // 获取所有 NAT 规则\n if (!e)\n goto null_bind;\n \n for (i = 0; i < e->num_hook_entries; i++) { // 依次执行 NAT 规则\n if (e->hooks[i].hook(e->hooks[i].priv, skb, state) != NF_ACCEPT )\n return ret; // 任何规则返回非 NF_ACCEPT,就停止当前处理\n \n if (nf_nat_initialized(ct, maniptype))\n goto do_nat;\n }\nnull_bind:\n nf_nat_alloc_null_binding(ct, state->hook);\n } else { // Already setup manip\n if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))\n goto oif_changed;\n }\n break;\n default: /* ESTABLISHED */\n if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))\n goto oif_changed;\n }\ndo_nat:\n return nf_nat_packet(ct, ctinfo, state->hook, skb);\noif_changed:\n nf_ct_kill_acct(ct, ctinfo, skb);\n return NF_DROP;\n}\n```\n\n首先查询 conntrack 记录,如果不存在,就意味着无法跟踪这个连接,那就更不可能做 NAT 了,因此直接返回。\n\n如果找到了 conntrack 记录,并且是 、 或 状态,就去获取 NAT 规则。如果没有规则,直接返回 ,对包不 做任何改动;如果有规则,最后执行 ,这个函数会进一步调用 完成对包的修改,如果失败,包将被丢弃。\n\n### Masquerade\n\nNAT 模块\n\nMasquerade 优缺点:\n\n### 4.6 :执行 NAT\n\n\n\n```\n// net/netfilter/nf_nat_core.c\n \n/* Do packet manipulations according to nf_nat_setup_info. */\nunsigned int nf_nat_packet(struct nf_conn *ct, enum ip_conntrack_info ctinfo,\n unsigned int hooknum, struct sk_buff *skb)\n{\n enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);\n enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);\n unsigned int verdict = NF_ACCEPT;\n \n statusbit = (mtype == NF_NAT_MANIP_SRC? IPS_SRC_NAT : IPS_DST_NAT)\n \n if (dir == IP_CT_DIR_REPLY) // Invert if this is reply dir\n statusbit ^= IPS_NAT_MASK;\n \n if (ct->status & statusbit) // Non-atomic: these bits don\'t change. */\n verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);\n \n return verdict;\n}\n```\n\n\n\n\n\n\n```\nstatic unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,\n enum nf_nat_manip_type mtype, enum ip_conntrack_dir dir)\n{\n struct nf_conntrack_tuple target;\n \n /* We are aiming to look like inverse of other direction. */\n nf_ct_invert_tuplepr(&target, &ct->tuplehash[!dir].tuple);\n \n l3proto = __nf_nat_l3proto_find(target.src.l3num);\n l4proto = __nf_nat_l4proto_find(target.src.l3num, target.dst.protonum);\n if (!l3proto->manip_pkt(skb, 0, l4proto, &target, mtype)) // 协议相关处理\n return NF_DROP;\n \n return NF_ACCEPT;\n}\n```\n\n## 5. 配置和监控\n\n### 5.1 查看/加载/卸载 nf_conntrack 模块\n\n\n\n```\n$ modinfo nf_conntrack\nfilename: /lib/modules/4.19.118-1.el7.centos.x86_64/kernel/net/netfilter/nf_conntrack.ko\nlicense: GPL\nalias: nf_conntrack-10\nalias: nf_conntrack-2\nalias: ip_conntrack\nsrcversion: 4BBDB5BBEF460DF5F079C59\ndepends: nf_defrag_ipv6,libcrc32c,nf_defrag_ipv4\nretpoline: Y\nintree: Y\nname: nf_conntrack\nvermagic: 4.19.118-1.el7.centos.x86_64 SMP mod_unload modversions\nparm: tstamp:Enable connection tracking flow timestamping. (bool)\nparm: acct:Enable connection tracking flow accounting. (bool)\nparm: nf_conntrack_helper:Enable automatic conntrack helper assignment (default 0) (bool)\nparm: expect_hashsize:uint\n```\n\n卸载:\n\n\n\n```\n$ rmmod nf_conntrack_netlink nf_conntrack\n```\n\n重新加载:\n\n\n\n```\n$ modprobe nf_conntrack\n \n# 加载时还可以指定额外的配置参数,例如:\n$ modprobe nf_conntrack nf_conntrack_helper=1 expect_hashsize=131072\n```\n\n### 5.2 sysctl 配置项\n\n\n\n```\n$ sysctl -a | grep nf_conntrack\nnet.netfilter.nf_conntrack_acct = 0\nnet.netfilter.nf_conntrack_buckets = 262144 # hashsize = nf_conntrack_max/nf_conntrack_buckets\nnet.netfilter.nf_conntrack_checksum = 1\nnet.netfilter.nf_conntrack_count = 2148\n... # DCCP options\nnet.netfilter.nf_conntrack_events = 1\nnet.netfilter.nf_conntrack_expect_max = 1024\n... # IPv6 options\nnet.netfilter.nf_conntrack_generic_timeout = 600\nnet.netfilter.nf_conntrack_helper = 0\nnet.netfilter.nf_conntrack_icmp_timeout = 30\nnet.netfilter.nf_conntrack_log_invalid = 0\nnet.netfilter.nf_conntrack_max = 1048576 # conntrack table size\n... # SCTP options\nnet.netfilter.nf_conntrack_tcp_be_liberal = 0\nnet.netfilter.nf_conntrack_tcp_loose = 1\nnet.netfilter.nf_conntrack_tcp_max_retrans = 3\nnet.netfilter.nf_conntrack_tcp_timeout_close = 10\nnet.netfilter.nf_conntrack_tcp_timeout_close_wait = 60\nnet.netfilter.nf_conntrack_tcp_timeout_established = 21600\nnet.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120\nnet.netfilter.nf_conntrack_tcp_timeout_last_ack = 30\nnet.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300\nnet.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60\nnet.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120\nnet.netfilter.nf_conntrack_tcp_timeout_time_wait = 120\nnet.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300\nnet.netfilter.nf_conntrack_timestamp = 0\nnet.netfilter.nf_conntrack_udp_timeout = 30\nnet.netfilter.nf_conntrack_udp_timeout_stream = 180\n```\n\n### 5.3 监控\n\n### 丢包监控\n\n 下面有一些关于 conntrack 的详细统计:\n\n\n\n```\n$ cat /proc/net/stat/nf_conntrack\nentries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart\n000008e3 00000000 00000000 00000000 0000309d 001e72d4 00000000 00000000 00000000 00000000 00000000 00000000 000000ee 00000000 00000000 00000000 000368d7\n000008e3 00000000 00000000 00000000 00007301 002b8e8c 00000000 00000000 00000000 00000000 00000000 00000000 00000170 00000000 00000000 00000000 00035794\n000008e3 00000000 00000000 00000000 00001eea 001e6382 00000000 00000000 00000000 00000000 00000000 00000000 00000059 00000000 00000000 00000000 0003f166\n...\n```\n\n此外,还可以用 命令:\n\n\n\n```\n$ conntrack -S\ncpu=0 found=0 invalid=743150 ignore=238069 insert=0 insert_failed=0 drop=195603 early_drop=118583 error=16 search_restart=22391652\ncpu=1 found=0 invalid=2004 ignore=402790 insert=0 insert_failed=0 drop=44371 early_drop=34890 error=0 search_restart=1225447\n...\n```\n\n### conntrack table 使用量监控\n\n可以定期采集系统的 conntrack 使用量,\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_count\n257273\n```\n\n并与最大值比较:\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_max\n262144\n```\n\n## 6. 常见问题\n\n### 6.1 连接太多导致 conntrack table 被打爆\n\n### 现象\n\n业务层(应用层)现象\n\n网络层现象\n\n操作系统层现象\n\n内核日志中有如下报错:\n\n\n\n```\n$ demsg -T\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n...\n```\n\n另外, 或 能看到有 drop 统计。\n\n### 确认 conntrack table 被打爆\n\n遇到以上现象,基本就是 conntrack 表被打爆了。确认:\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_count\n257273\n \n$ cat /proc/sys/net/netfilter/nf_conntrack_max\nnet.netfilter.nf_conntrack_max = 262144\n```\n\n如果有 conntrack count 监控会看的更清楚,因为我们命令行查看时,高峰可能过了。\n\n### 解决方式\n\n优先级从高到低:\n\n1.调大 conntrack 表\n\n运行时配置(经实际测试, **不会对现有连接造成影响** ):\n\n\n\n```\n $ sysctl -w net.netfilter.nf_conntrack_max=524288\n $ sysctl -w net.netfilter.nf_conntrack_buckets=131072 # 推荐配置 hashsize=nf_conntrack_count/4\n```\n\n持久化配置:\n\n\n\n```\n$ echo \'net.netfilter.nf_conntrack_max = 524288\' >> /etc/sysctl.conf\n$ echo \'net.netfilter.nf_conntrack_buckets = 131072\' >> /etc/sysctl.conf\n```\n\n影响:连接跟踪模块 **会多用一些内存** 。具体多用多少内存,可参考 \n\n[附录](https://arthurchiao.art/blog/conntrack-design-and-implementation-zh/%23ch_8.2)。\n\n2.减小 GC 时间\n\n还可以调小 conntrack 的 GC(也叫 timeout)时间,加快过期 entry 的回收。\n\n 针对不同 TCP 状态(established、fin_wait、time_wait 等)的 entry 有不同的 GC 时间。\n例如, **默认的 established 状态的 GC 时间是 423000s(5 天)** 。设置成这么长的 **可能原因** 是:TCP/IP 协议中允许 established 状态的连接无限期不发送任何东西(但仍然活着) [8],协议的具体实现(Linux、BSD、Windows 等)会设置各自允许的最大 idle timeout。为防止 GC 掉这样长时间没流量但实际还活着的连接,就设置一个足够保守的 timeout 时间。[8] 中建议这个值不小于 2 小时 4 分钟(作为对比和参考, **Cilium 自己实现的 CT 中,默认 established GC 是 6 小时** )。 但也能看到一些厂商推荐比这个小得多的配置,例如 20 分钟。\n如果对自己的网络环境和需求非常清楚,那可以将这个时间调到一个合理的、足够小的值; 如果不是非常确定的话,还是 **建议保守一些,例如设置 6 个小时** —— 这已经比默认值 5 天小多了。\n\n$ sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established = 21600\n\n持久化:\n\n$ echo \'net.netfilter.nf_conntrack_tcp_timeout_established = 21600\' >> /etc/sysctl.conf\n\n其他几个 timeout 值(尤其是 ,默认 )也可以适当调小, 但还是那句话: **如果不确定潜在后果,千万不要激进地调小** 。\n\n## 7. 总结\n\n连接跟踪是一个非常基础且重要的网络模块,但只有在少数场景下才会引起普通开发者的注意。\n\n例如,L4LB 短时高并发场景下,LB 节点每秒接受大量并发短连接,可能导致 conntrack table 被打爆。此时的现象是:\n\n此时的原因可能是 conntrack table 太小,也可能是 GC 不够及 时,甚至是 GC 有bug。\n\n## 8. 附录\n\n### 8.1 第一个 SYN 包的重传间隔计算(Linux 4.19.118 实现)\n\n调用路径:。\n\n\n\n```\n// net/ipv4/tcp_output.c\n/* Do all connect socket setups that can be done AF independent. */\nstatic void tcp_connect_init(struct sock *sk)\n{\n inet_csk(sk)->icsk_rto = tcp_timeout_init(sk);\n ...\n}\n \n// include/net/tcp.h\nstatic inline u32 tcp_timeout_init(struct sock *sk)\n{\n // 获取 SYN-RTO:如果这个 socket 上没有 BPF 程序,或者有 BPF 程序但执行失败,都返回 -1\n // 除非用户自己编写 BPF 程序并 attach 到 cgroup/socket,否则这里都是没有 BPF 的,因此这里返回 -1\n timeout = tcp_call_bpf(sk, BPF_SOCK_OPS_TIMEOUT_INIT, 0, NULL);\n \n if (timeout <= 0) // timeout == -1,接下来使用默认值\n timeout = TCP_TIMEOUT_INIT; // 宏定义,等于系统的 HZ 数,也就是 1 秒,见下面\n return timeout;\n}\n \n// include/net/tcp.h\n#define TCP_RTO_MAX ((unsigned)(120*HZ))\n#define TCP_RTO_MIN ((unsigned)(HZ/5))\n#define TCP_TIMEOUT_MIN (2U) /* Min timeout for TCP timers in jiffies */\n#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC6298 2.1 initial RTO value */\n```\n\n### 8.2 根据 nf_conntrack_max 计算 conntrack 模块所需的内存\n\n\n\n```\n$ cat /proc/slabinfo | head -n2; cat /proc/slabinfo | grep conntrack\nslabinfo - version: 2.1\n# name
\n\nFig. NAT\n\n\n\n```\nunsigned int\nnf_nat_inet_fn(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)\n{\n ct = nf_ct_get(skb, &ctinfo);\n if (!ct) // conntrack 不存在就做不了 NAT,直接返回,这也是我们为什么说 NAT 依赖 conntrack 的结果\n return NF_ACCEPT;\n \n nat = nfct_nat(ct);\n \n switch (ctinfo) {\n case IP_CT_RELATED:\n case IP_CT_RELATED_REPLY: /* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */\n case IP_CT_NEW: /* Seen it before? This can happen for loopback, retrans, or local packets. */\n if (!nf_nat_initialized(ct, maniptype)) {\n struct nf_hook_entries *e = rcu_dereference(lpriv->entries); // 获取所有 NAT 规则\n if (!e)\n goto null_bind;\n \n for (i = 0; i < e->num_hook_entries; i++) { // 依次执行 NAT 规则\n if (e->hooks[i].hook(e->hooks[i].priv, skb, state) != NF_ACCEPT )\n return ret; // 任何规则返回非 NF_ACCEPT,就停止当前处理\n \n if (nf_nat_initialized(ct, maniptype))\n goto do_nat;\n }\nnull_bind:\n nf_nat_alloc_null_binding(ct, state->hook);\n } else { // Already setup manip\n if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))\n goto oif_changed;\n }\n break;\n default: /* ESTABLISHED */\n if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))\n goto oif_changed;\n }\ndo_nat:\n return nf_nat_packet(ct, ctinfo, state->hook, skb);\noif_changed:\n nf_ct_kill_acct(ct, ctinfo, skb);\n return NF_DROP;\n}\n```\n\n首先查询 conntrack 记录,如果不存在,就意味着无法跟踪这个连接,那就更不可能做 NAT 了,因此直接返回。\n\n如果找到了 conntrack 记录,并且是 、 或 状态,就去获取 NAT 规则。如果没有规则,直接返回 ,对包不 做任何改动;如果有规则,最后执行 ,这个函数会进一步调用 完成对包的修改,如果失败,包将被丢弃。\n\n### Masquerade\n\nNAT 模块\n\nMasquerade 优缺点:\n\n### 4.6 :执行 NAT\n\n\n\n```\n// net/netfilter/nf_nat_core.c\n \n/* Do packet manipulations according to nf_nat_setup_info. */\nunsigned int nf_nat_packet(struct nf_conn *ct, enum ip_conntrack_info ctinfo,\n unsigned int hooknum, struct sk_buff *skb)\n{\n enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);\n enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);\n unsigned int verdict = NF_ACCEPT;\n \n statusbit = (mtype == NF_NAT_MANIP_SRC? IPS_SRC_NAT : IPS_DST_NAT)\n \n if (dir == IP_CT_DIR_REPLY) // Invert if this is reply dir\n statusbit ^= IPS_NAT_MASK;\n \n if (ct->status & statusbit) // Non-atomic: these bits don\'t change. */\n verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);\n \n return verdict;\n}\n```\n\n\n\n\n\n\n```\nstatic unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,\n enum nf_nat_manip_type mtype, enum ip_conntrack_dir dir)\n{\n struct nf_conntrack_tuple target;\n \n /* We are aiming to look like inverse of other direction. */\n nf_ct_invert_tuplepr(&target, &ct->tuplehash[!dir].tuple);\n \n l3proto = __nf_nat_l3proto_find(target.src.l3num);\n l4proto = __nf_nat_l4proto_find(target.src.l3num, target.dst.protonum);\n if (!l3proto->manip_pkt(skb, 0, l4proto, &target, mtype)) // 协议相关处理\n return NF_DROP;\n \n return NF_ACCEPT;\n}\n```\n\n## 5. 配置和监控\n\n### 5.1 查看/加载/卸载 nf_conntrack 模块\n\n\n\n```\n$ modinfo nf_conntrack\nfilename: /lib/modules/4.19.118-1.el7.centos.x86_64/kernel/net/netfilter/nf_conntrack.ko\nlicense: GPL\nalias: nf_conntrack-10\nalias: nf_conntrack-2\nalias: ip_conntrack\nsrcversion: 4BBDB5BBEF460DF5F079C59\ndepends: nf_defrag_ipv6,libcrc32c,nf_defrag_ipv4\nretpoline: Y\nintree: Y\nname: nf_conntrack\nvermagic: 4.19.118-1.el7.centos.x86_64 SMP mod_unload modversions\nparm: tstamp:Enable connection tracking flow timestamping. (bool)\nparm: acct:Enable connection tracking flow accounting. (bool)\nparm: nf_conntrack_helper:Enable automatic conntrack helper assignment (default 0) (bool)\nparm: expect_hashsize:uint\n```\n\n卸载:\n\n\n\n```\n$ rmmod nf_conntrack_netlink nf_conntrack\n```\n\n重新加载:\n\n\n\n```\n$ modprobe nf_conntrack\n \n# 加载时还可以指定额外的配置参数,例如:\n$ modprobe nf_conntrack nf_conntrack_helper=1 expect_hashsize=131072\n```\n\n### 5.2 sysctl 配置项\n\n\n\n```\n$ sysctl -a | grep nf_conntrack\nnet.netfilter.nf_conntrack_acct = 0\nnet.netfilter.nf_conntrack_buckets = 262144 # hashsize = nf_conntrack_max/nf_conntrack_buckets\nnet.netfilter.nf_conntrack_checksum = 1\nnet.netfilter.nf_conntrack_count = 2148\n... # DCCP options\nnet.netfilter.nf_conntrack_events = 1\nnet.netfilter.nf_conntrack_expect_max = 1024\n... # IPv6 options\nnet.netfilter.nf_conntrack_generic_timeout = 600\nnet.netfilter.nf_conntrack_helper = 0\nnet.netfilter.nf_conntrack_icmp_timeout = 30\nnet.netfilter.nf_conntrack_log_invalid = 0\nnet.netfilter.nf_conntrack_max = 1048576 # conntrack table size\n... # SCTP options\nnet.netfilter.nf_conntrack_tcp_be_liberal = 0\nnet.netfilter.nf_conntrack_tcp_loose = 1\nnet.netfilter.nf_conntrack_tcp_max_retrans = 3\nnet.netfilter.nf_conntrack_tcp_timeout_close = 10\nnet.netfilter.nf_conntrack_tcp_timeout_close_wait = 60\nnet.netfilter.nf_conntrack_tcp_timeout_established = 21600\nnet.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120\nnet.netfilter.nf_conntrack_tcp_timeout_last_ack = 30\nnet.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300\nnet.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60\nnet.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120\nnet.netfilter.nf_conntrack_tcp_timeout_time_wait = 120\nnet.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300\nnet.netfilter.nf_conntrack_timestamp = 0\nnet.netfilter.nf_conntrack_udp_timeout = 30\nnet.netfilter.nf_conntrack_udp_timeout_stream = 180\n```\n\n### 5.3 监控\n\n### 丢包监控\n\n 下面有一些关于 conntrack 的详细统计:\n\n\n\n```\n$ cat /proc/net/stat/nf_conntrack\nentries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart\n000008e3 00000000 00000000 00000000 0000309d 001e72d4 00000000 00000000 00000000 00000000 00000000 00000000 000000ee 00000000 00000000 00000000 000368d7\n000008e3 00000000 00000000 00000000 00007301 002b8e8c 00000000 00000000 00000000 00000000 00000000 00000000 00000170 00000000 00000000 00000000 00035794\n000008e3 00000000 00000000 00000000 00001eea 001e6382 00000000 00000000 00000000 00000000 00000000 00000000 00000059 00000000 00000000 00000000 0003f166\n...\n```\n\n此外,还可以用 命令:\n\n\n\n```\n$ conntrack -S\ncpu=0 found=0 invalid=743150 ignore=238069 insert=0 insert_failed=0 drop=195603 early_drop=118583 error=16 search_restart=22391652\ncpu=1 found=0 invalid=2004 ignore=402790 insert=0 insert_failed=0 drop=44371 early_drop=34890 error=0 search_restart=1225447\n...\n```\n\n### conntrack table 使用量监控\n\n可以定期采集系统的 conntrack 使用量,\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_count\n257273\n```\n\n并与最大值比较:\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_max\n262144\n```\n\n## 6. 常见问题\n\n### 6.1 连接太多导致 conntrack table 被打爆\n\n### 现象\n\n业务层(应用层)现象\n\n网络层现象\n\n操作系统层现象\n\n内核日志中有如下报错:\n\n\n\n```\n$ demsg -T\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n[Tue Apr 6 18:12:30 2021] nf_conntrack: nf_conntrack: table full, dropping packet\n...\n```\n\n另外, 或 能看到有 drop 统计。\n\n### 确认 conntrack table 被打爆\n\n遇到以上现象,基本就是 conntrack 表被打爆了。确认:\n\n\n\n```\n$ cat /proc/sys/net/netfilter/nf_conntrack_count\n257273\n \n$ cat /proc/sys/net/netfilter/nf_conntrack_max\nnet.netfilter.nf_conntrack_max = 262144\n```\n\n如果有 conntrack count 监控会看的更清楚,因为我们命令行查看时,高峰可能过了。\n\n### 解决方式\n\n优先级从高到低:\n\n1.调大 conntrack 表\n\n运行时配置(经实际测试, **不会对现有连接造成影响** ):\n\n\n\n```\n $ sysctl -w net.netfilter.nf_conntrack_max=524288\n $ sysctl -w net.netfilter.nf_conntrack_buckets=131072 # 推荐配置 hashsize=nf_conntrack_count/4\n```\n\n持久化配置:\n\n\n\n```\n$ echo \'net.netfilter.nf_conntrack_max = 524288\' >> /etc/sysctl.conf\n$ echo \'net.netfilter.nf_conntrack_buckets = 131072\' >> /etc/sysctl.conf\n```\n\n影响:连接跟踪模块 **会多用一些内存** 。具体多用多少内存,可参考 \n\n[附录](https://arthurchiao.art/blog/conntrack-design-and-implementation-zh/%23ch_8.2)。\n\n2.减小 GC 时间\n\n还可以调小 conntrack 的 GC(也叫 timeout)时间,加快过期 entry 的回收。\n\n 针对不同 TCP 状态(established、fin_wait、time_wait 等)的 entry 有不同的 GC 时间。\n例如, **默认的 established 状态的 GC 时间是 423000s(5 天)** 。设置成这么长的 **可能原因** 是:TCP/IP 协议中允许 established 状态的连接无限期不发送任何东西(但仍然活着) [8],协议的具体实现(Linux、BSD、Windows 等)会设置各自允许的最大 idle timeout。为防止 GC 掉这样长时间没流量但实际还活着的连接,就设置一个足够保守的 timeout 时间。[8] 中建议这个值不小于 2 小时 4 分钟(作为对比和参考, **Cilium 自己实现的 CT 中,默认 established GC 是 6 小时** )。 但也能看到一些厂商推荐比这个小得多的配置,例如 20 分钟。\n如果对自己的网络环境和需求非常清楚,那可以将这个时间调到一个合理的、足够小的值; 如果不是非常确定的话,还是 **建议保守一些,例如设置 6 个小时** —— 这已经比默认值 5 天小多了。\n\n$ sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established = 21600\n\n持久化:\n\n$ echo \'net.netfilter.nf_conntrack_tcp_timeout_established = 21600\' >> /etc/sysctl.conf\n\n其他几个 timeout 值(尤其是 ,默认 )也可以适当调小, 但还是那句话: **如果不确定潜在后果,千万不要激进地调小** 。\n\n## 7. 总结\n\n连接跟踪是一个非常基础且重要的网络模块,但只有在少数场景下才会引起普通开发者的注意。\n\n例如,L4LB 短时高并发场景下,LB 节点每秒接受大量并发短连接,可能导致 conntrack table 被打爆。此时的现象是:\n\n此时的原因可能是 conntrack table 太小,也可能是 GC 不够及 时,甚至是 GC 有bug。\n\n## 8. 附录\n\n### 8.1 第一个 SYN 包的重传间隔计算(Linux 4.19.118 实现)\n\n调用路径:。\n\n\n\n```\n// net/ipv4/tcp_output.c\n/* Do all connect socket setups that can be done AF independent. */\nstatic void tcp_connect_init(struct sock *sk)\n{\n inet_csk(sk)->icsk_rto = tcp_timeout_init(sk);\n ...\n}\n \n// include/net/tcp.h\nstatic inline u32 tcp_timeout_init(struct sock *sk)\n{\n // 获取 SYN-RTO:如果这个 socket 上没有 BPF 程序,或者有 BPF 程序但执行失败,都返回 -1\n // 除非用户自己编写 BPF 程序并 attach 到 cgroup/socket,否则这里都是没有 BPF 的,因此这里返回 -1\n timeout = tcp_call_bpf(sk, BPF_SOCK_OPS_TIMEOUT_INIT, 0, NULL);\n \n if (timeout <= 0) // timeout == -1,接下来使用默认值\n timeout = TCP_TIMEOUT_INIT; // 宏定义,等于系统的 HZ 数,也就是 1 秒,见下面\n return timeout;\n}\n \n// include/net/tcp.h\n#define TCP_RTO_MAX ((unsigned)(120*HZ))\n#define TCP_RTO_MIN ((unsigned)(HZ/5))\n#define TCP_TIMEOUT_MIN (2U) /* Min timeout for TCP timers in jiffies */\n#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC6298 2.1 initial RTO value */\n```\n\n### 8.2 根据 nf_conntrack_max 计算 conntrack 模块所需的内存\n\n\n\n```\n$ cat /proc/slabinfo | head -n2; cat /proc/slabinfo | grep conntrack\nslabinfo - version: 2.1\n# name \n\n[https://zhuanlan.zhihu.com/p/703880283](https://zhuanlan.zhihu.com/p/703880283)
\n -->

关于博主
an actually real engineer
通信工程专业毕业,7年开发经验
技术栈:
精通c/c++
精通golang
熟悉常见的脚本,js,lua,python,php
熟悉电路基础,嵌入式,单片机
耕耘领域:
服务端开发
嵌入式开发
>gin接口代码CURD生成工具
sql ddl to struct and markdown,将sql表自动化生成代码内对应的结构体和markdown表格格式,节省宝贵的时间。
qt .ui文件转css文件
duilib xml 自动生成绑定控件代码
协议调试器
基于lua虚拟机的的协议调试器软件 支持的协议有:
串口
tcp客户端/服务端
udp 组播/udp节点
tcp websocket 客户端/服务端
软件界面

使用例子: 通过脚本来获得接收到的数据并写入文件和展示在界面上
下载地址和源码
webrtc easy demo
webrtc c++ native 库 demo 实现功能:
基于QT
webrtc摄像头/桌面捕获功能
opengl渲染/多播放窗格管理
janus meeting room
下载地址和源码
wifi,蓝牙 - 无线开关
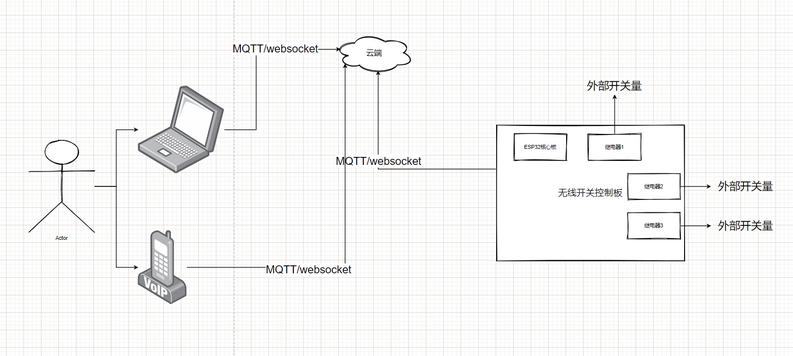
实现功能:
通过wifi/蓝牙实现远程开关电器或者其他电子设备
电路原理图:
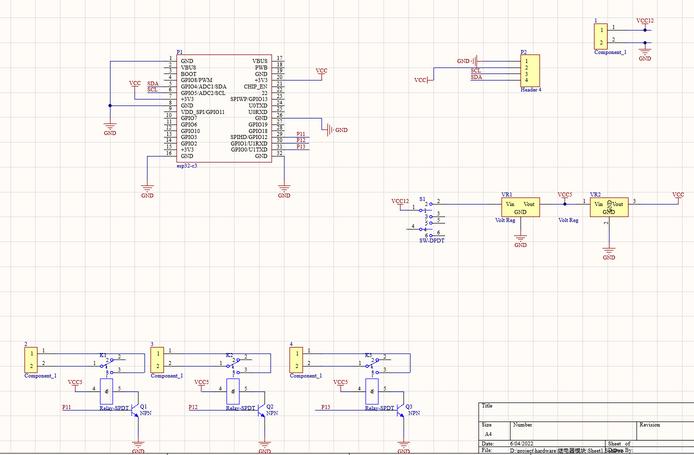
实物图:

深度学习验证工具
虚拟示波器
硬件实物图:

实现原理
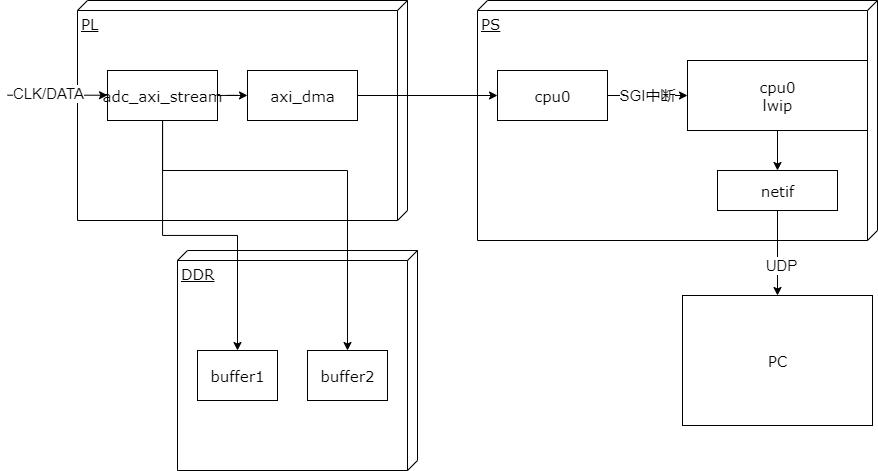
基本性能
采集频率: 取决于外部adc模块和ebaz4205矿板的以太网接口速率,最高可以达到100M/8 约为12.5MPS
上位机实现功能: 采集,显示波形,存储wave文件。
参数可运行时配置
上位机:

显示缓冲区大小可调
刷新率可调节
触发显示刷新可调节

又一个modbus调试工具
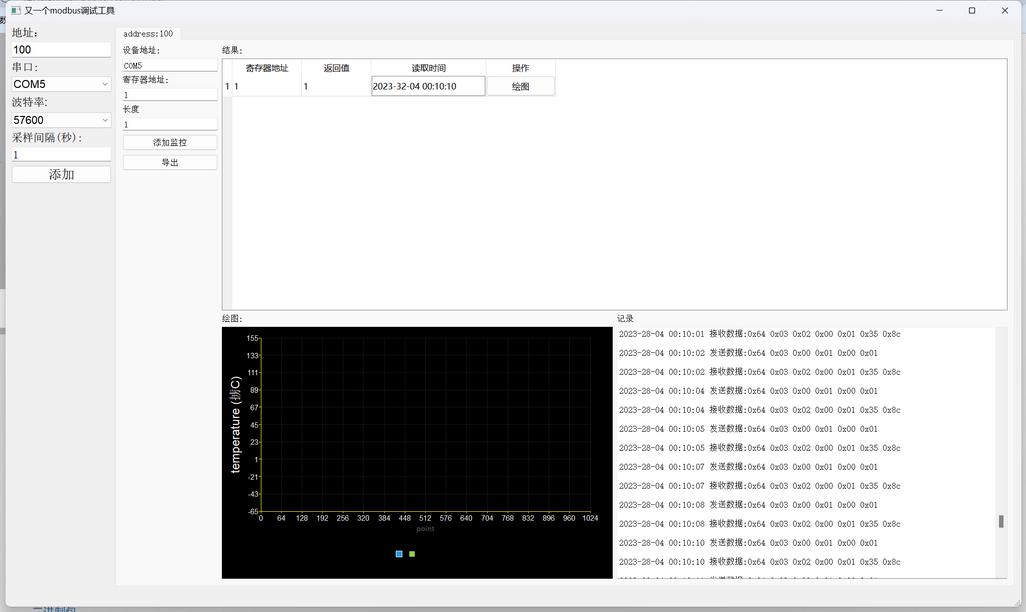
最近混迹物联网企业,发现目前缺少一个简易可用的modbus调试工具,本软件旨在为开发者提供一个简单modbus测试工具。 主打一个代码简单易修改。 特点:
1. 基于QT5
2. 基于libmodbus
3. 三方库完全跨平台,linux/windows。
开源plutosdr 板卡

1. 完全开源
2. 提高固件定制服务
3. 硬件售价450 手焊产量有线
测试数据
内部DDS回环测试

接收测试
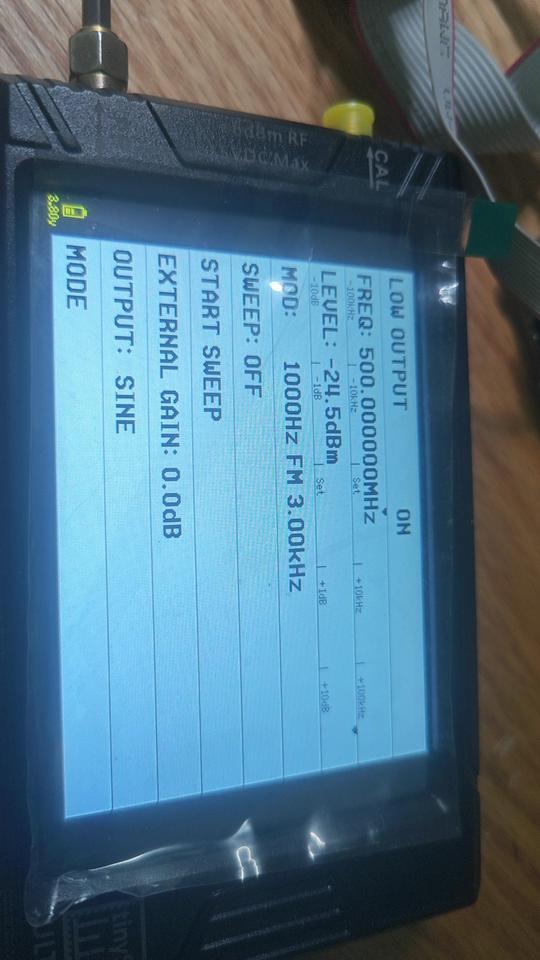
外部发送500MHZ FM波形
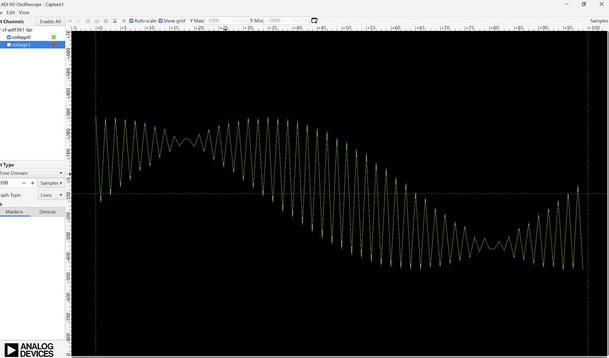
matlab测试

2TRX版本

大部分plutosdr应用场景都是讲plutosdr板卡作为射频收发器来使用。 实际上plutosdr板卡本身运行linux 操作系统。是具有一定脱机运算的能力。 对于一些微型频谱检测,简单射频信号收发等应用完全可以将应用层直接实现在板卡上 相较于通过网卡或者USB口传输具有更稳定,带宽更高等优点。 本开源板卡由于了SD卡启动,较原版pluto支持了自定义启动应用的功能。 提供了应用层开发SDK(编译器,buildroot文件系统)。 通过usb连接电脑,经过RNDIS驱动可以近似为通过网卡连接 (支持固件的开发定制)。
二次开发例子
``` all: arm-linux-gnueabihf-gcc -mfloat-abi=hard --sysroot=/root/v0.32_2trx/buildroot/output/staging -std=gnu99 -g -o pluto_stream ad9361-iiostream.c -lpthread -liio -lm -Wall -Wextra -lrt clean: rm pluto_stream
版面分析即分析出图片内的具体文件元素,如文档标题,文档内容,文档页码等,本工具基于cnstd模型